
USA Registered IP Patent
Intellectual property coverage presented through USPTO filing evidence and patent registry details.
 RapidsDB
ASEAN
RapidsDB
ASEAN



World Leading Real-time Big Data Analytics Platform.
Company profile
Rapids Data was founded in 2014 and is dual headquartered in Beijing, China and Silicon Valley, USA.
The company is an industry leader in the research and development of big data real-time processing and analysis, providing advanced and innovative big data technology, products, services and total solutions to the global market.
The RapidsDB Unified Analytics Platform is an integrated real-time, AI-based, big data analytics platform that can be deployed on premises or in the Cloud.
RapidsDB offers a fully parallel, distributed, in-memory federated query system designed to support complex analytical SQL queries across multiple data stores, producing integrated results at ultra-fast speed.
A pluggable connector-based framework, streaming data processing engine, and AI-enabled computing engine help build future-oriented data pipelines with high performance and cost effectiveness.
Trust signals
Intellectual property coverage presented through USPTO filing evidence and patent registry details.

Reference client logos and customer proof from the original company profile.
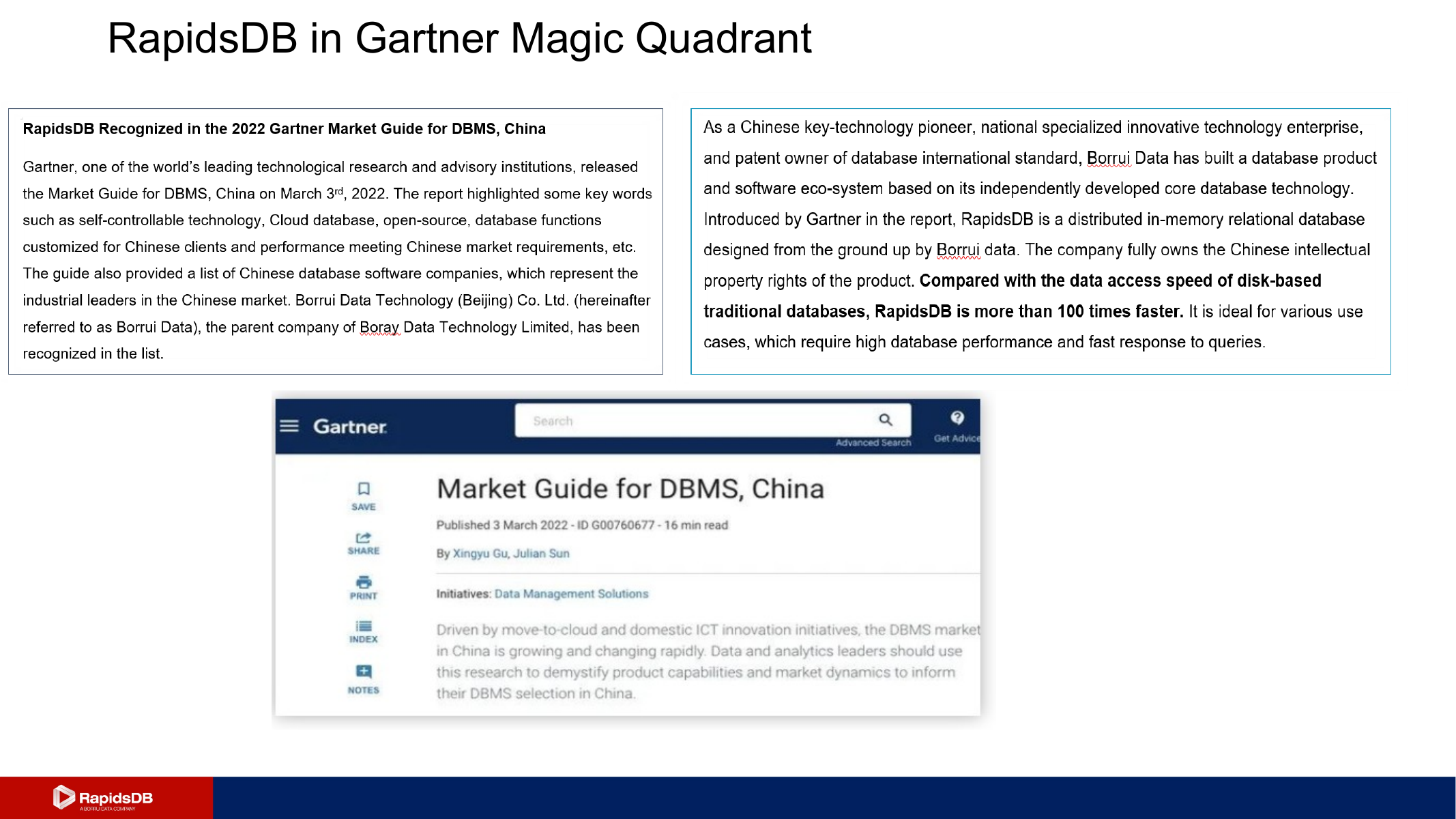
Market positioning reference included in the source presentation.

Certification and standards material carried over from the PPT.
Rapids Data Platform
The Rapids Data Platform focuses on big data real-time processing and provides real-time analytics solutions through an integrated product system.
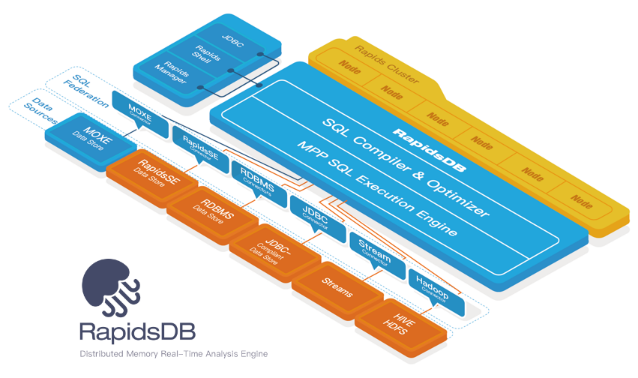
RapidsDB engine
RapidsDB accesses and processes data directly in memory. Query requests are broken into smaller tasks, distributed intelligently, and executed in parallel across nodes for real-time processing and analysis.
Performance comparison
Testing environment: 5-node server cluster. Each server has 2 CPU cores and 256GB memory.
RapidsDB test result compared with mainstream database providers in the source profile.
Rapids Federation
The embedded federated connector system enables users to access various data sources through industry-standard SQL and JDBC interfaces.
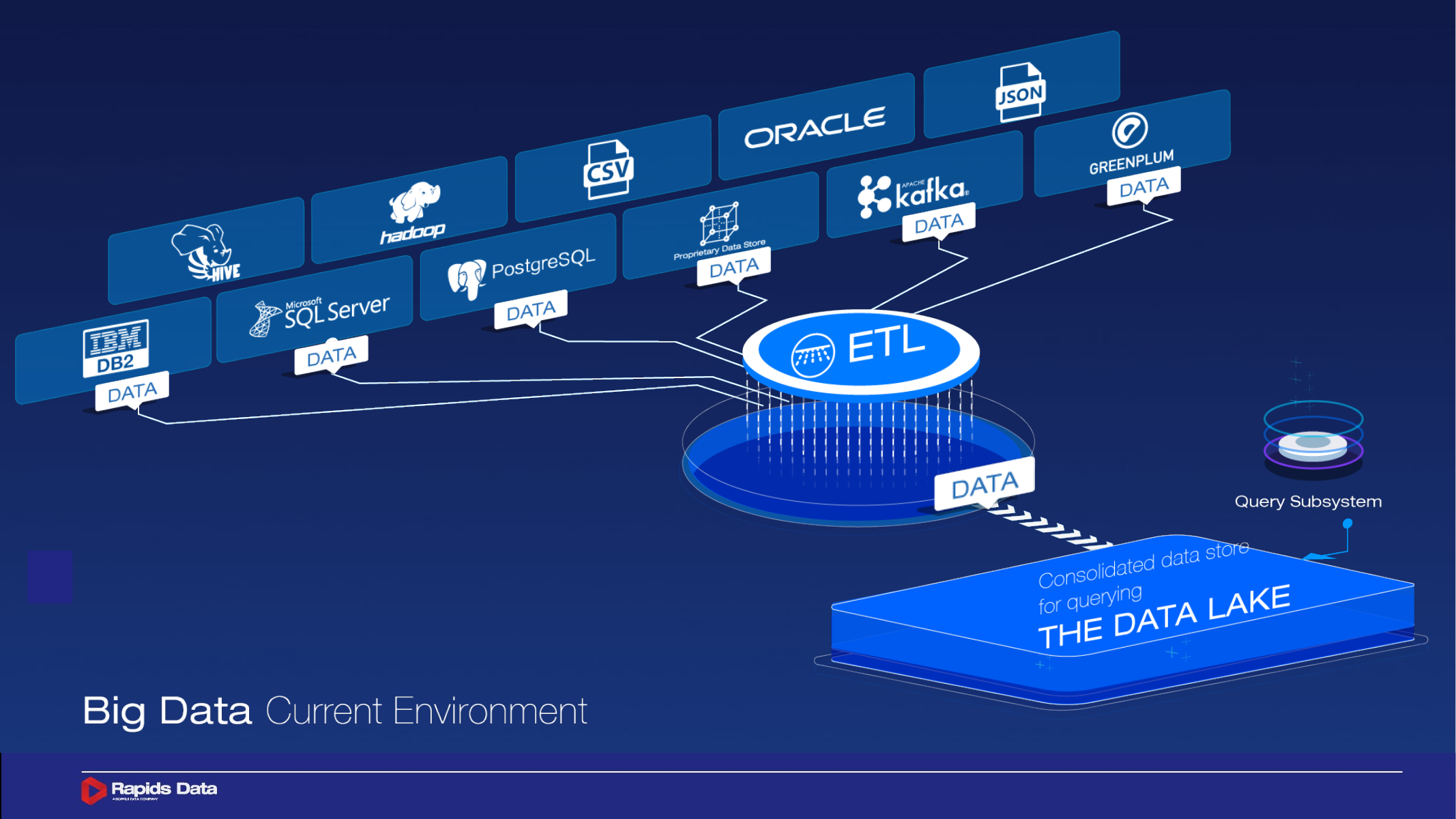
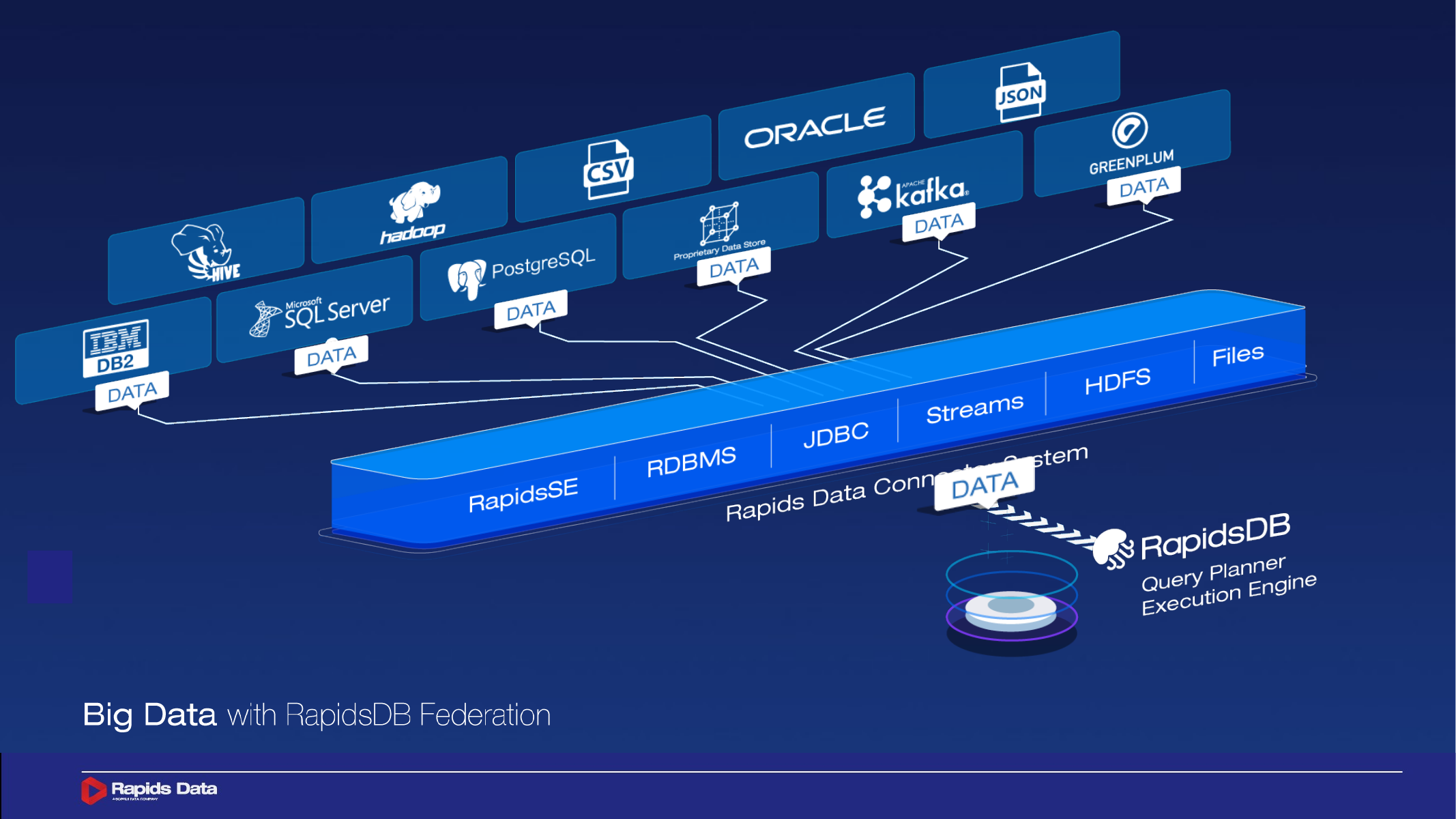
Product system
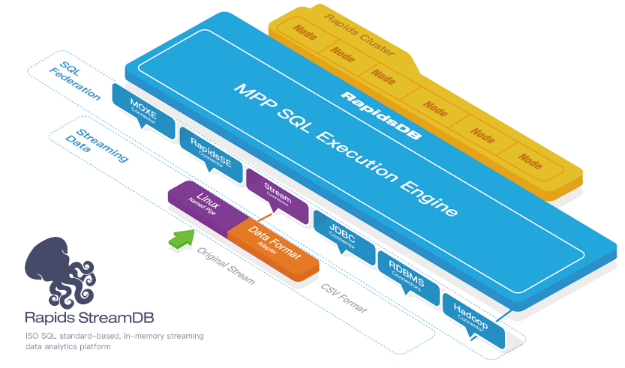
An ISO standard-based, in-memory streaming data processing engine that continuously analyzes streaming data within milliseconds.
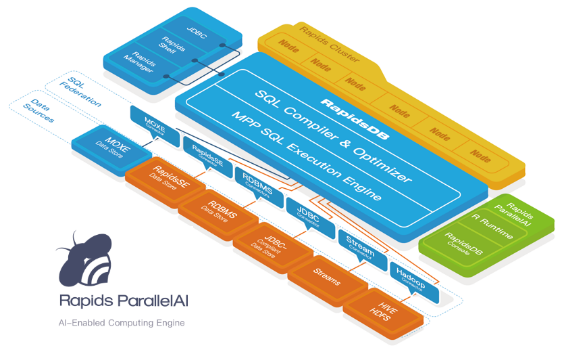
AI-enabled analytics with an in-memory, distributed, parallel implementation of the R language integrated within a RapidsDB cluster.
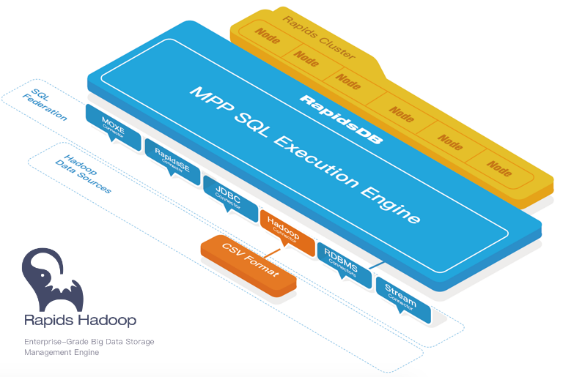
Enterprise-grade SQL-on-Hadoop based on open source Apache Hadoop technology, helping enterprises build data lakes through strictly size-controlled installation packages.
AI-In-A-Box
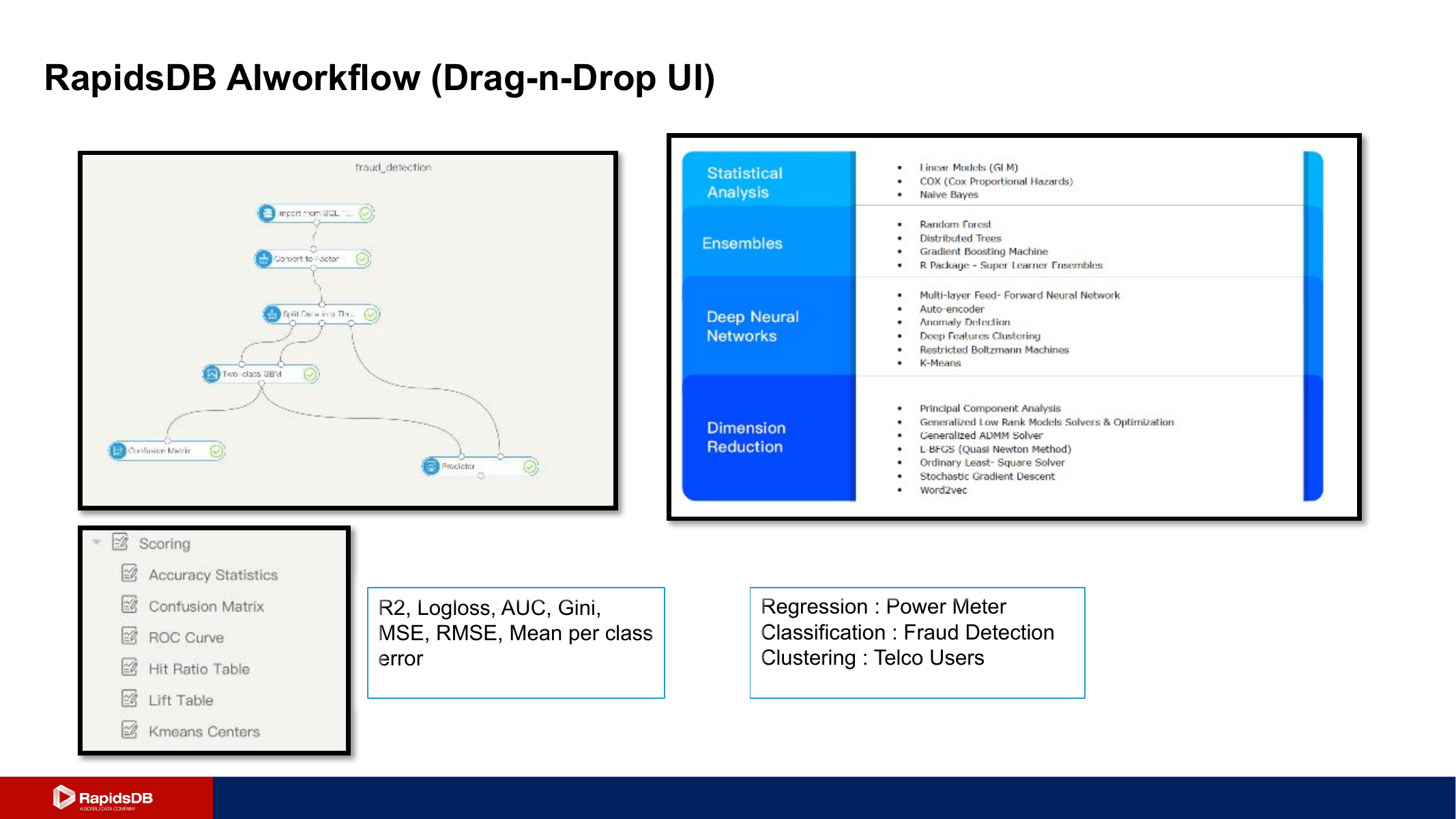
Data flow and AI workflow
RapidsDB connects edge and cloud data flow patterns with AI workflow tooling for regression, classification, and clustering use cases.
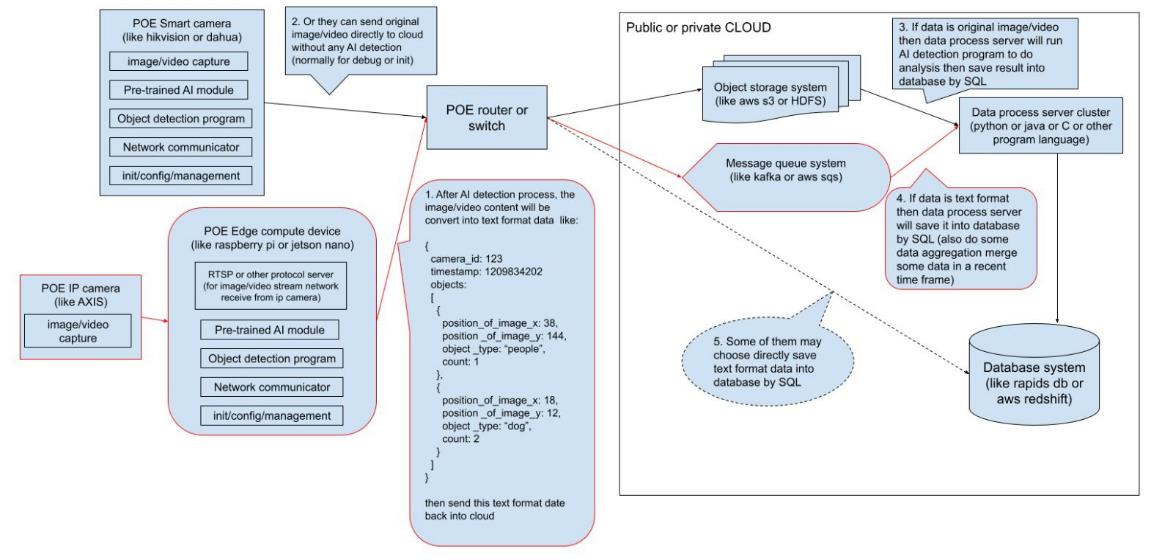
Applications
RapidsDB Unified Analytics Platform supports high-volume, low-latency analytics across industries.
Platform recap
Thank You
www.rapidsdb.co